The Death of Hash Keys

An innovation introduced in data vault 2.0 is the adoption of surrogate hash keys to join adjacent tables on. The act of hashing is particularly attractive in the domain of column uniqueness because:
- The same values provided as an input to hash generation will always provide the same output (consistent hashing).
- No matter the size of the input into a hash function the output will always be of the same byte length.
- Bytes generated as an output of hashing do not have any special characters and therefore do not need varchar as the data type to store that output. Varchar stores two bytes per character (UTF-8) because of the need to support a diverse character set beyond European languages (ASCII), hash digest values have no need for that extra byte and therefore hash digest values should be stored as a binary / raw data type.

What we do with hashing
Hashing has an element of randomness to the generated output in that the sequence of characters generated are likely different from each other. The same input will always generate the same output, the choice of hash function depends on the use case desired. A factor of a hash function’s strength is the uniqueness of the generated output, but that strength correlates to the processing power needed to generate that output (and therefore the time it takes to generate that output).
Why would we want less uniqueness versus more uniqueness in a hash output? Because the randomness is useful for the distribution of data in parallel processing and distributed computing where we do not necessarily rely on a hash digest’s uniqueness. For example, murmur2 (a non-cryptographic hash function) is used to distribute streams of data between topics so that topics are not overloaded. Mumur3 is used to distribute data across nodes in a Cassandra cluster. A hash digest’s uniqueness is not desirable here, only the speed of distribution and randomness to improve parallel distribution to Kafka topics and Cassandra nodes respectively.
This is the opposite desire when defining surrogate keys for a relational data model or determining if all the attributes that constitute a record is unique, let’s first define the type of surrogate keys we encounter in data modelling:
- Durable surrogate integer keys — durable means that the surrogate key value does not change, it is always one-to-one with the natural key that surrogate key represents. The prime benefit of doing this is to enable faster joins with the reduced byte representation and simplifying the join conditions to a single column between tables. New integer keys are typically assigned when a new natural key (or keys) is loaded in an incremental fashion.
- Durable surrogate hash keys — as above, except we are using a generated surrogate hash key instead. A new combination of natural keys will produce a different hash digest and therefore a new surrogate hash key.
- Temporal surrogate integer keys — Instead of assigning a surrogate per natural key, we assign a new incremental integer surrogate key per record. Because this assignment is time-bound, each new increment is essentially an increment by time you can reference or join on. The join is unique and will return the appropriate time-bound record. Essentially this surrogate key is what is assigned for each record in a dimension and referenced by the fact table. You select the correct slice of data you want across all dimensions of a metric or fact based on the date time dimension (and nothing else).
- Is there such a thing as temporal surrogate hash keys you ask? What would be the point of doing that if the act of assigning temporal surrogate integer keys bares almost no cost to your data administration except by simply defining a column as auto-increment / identity (0, 1)? The database itself generates the unique key for you, a temporal surrogate hash key means you have to do more work to generate that unique key.
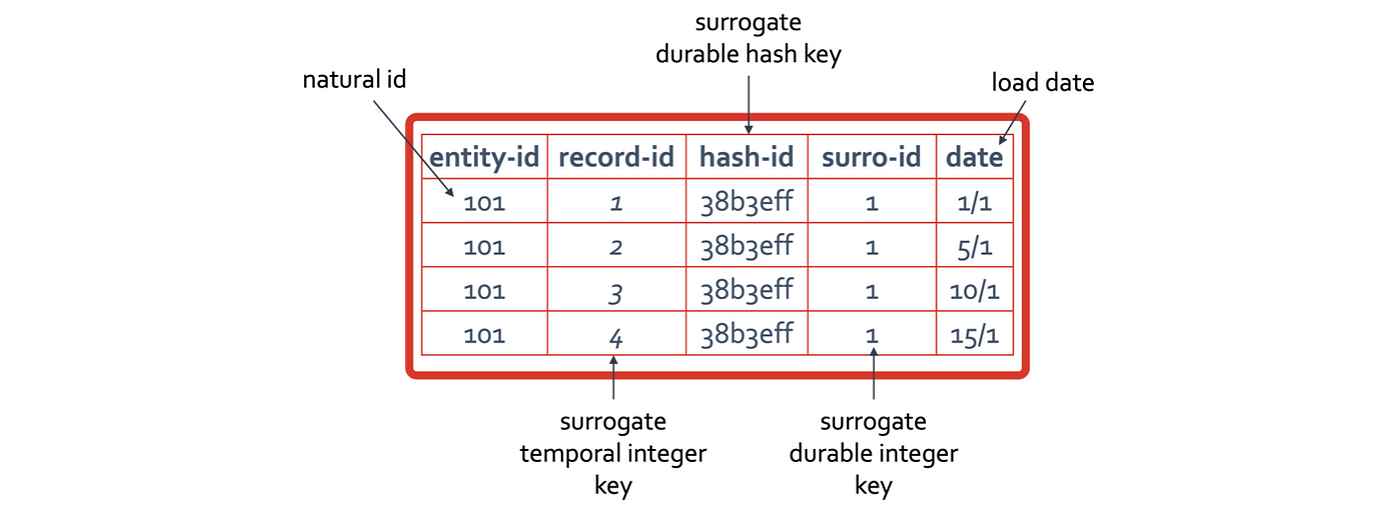
Recall that we used the same temporal surrogate integer concept in improving data vault’s point-in-time (PIT) table with the advent of the sequence-number-only (SNOPIT) a few years ago. It is the same concept applied in dimensional modelling that we second for data vault, see: bit.ly/3dn83n8
But why do we want surrogate keys in a data model? The benefits of using a surrogate key in data modelling are:
- We can use a single key column to perform a join between related tables, either the key is durable in that it has a one-to-one cardinality with a natural key or set of natural keys, or a single key represents that natural key at a point in time (as we have described above).
- The use of a surrogate presents a consistent data type to join relational tables, as well as a pattern for repeatable and scalable association between a naming / joining standard between tables (for example a hub table called hub_account may have a surrogate hash key column called dv_hashkey_hub_account by using the standard convention dv_hashkey_${parent-tablename}).
- The surrogate key can be used to encapsulate other non-natural key columns we would like to ensure uniqueness on, for example in the data vault we want to utilise business key collision codes and model tenancy ids as part of the input to a surrogate key assignment.
- Utilising a surrogate key may also be useful method for working with the data without exposing potentially identifying details a natural key may possess.
Kimball-styled data models should primarily use temporal surrogate integer keys to join facts and dimension tables together. Although slowly changing dimensions (SCD Type 2) provide analysts with ‘From’ and ‘To’ date columns to effectively pick the data they want based on a historical date, it is the wrong place to be slicing your data around the metrics / facts you need (in most cases). These temporal columns in a dimensional model are mechanisms to track changes in the data loaded, instead the job of querying the slice of data you need is based on the use of the datetime dimension. Yes, you should be picking your needed time slice based on the time dimension and equi-join the time dimension to the fact table and the foreign keys (which are temporal surrogate keys) will point to the dimensional records applicable to the metrics you desire.
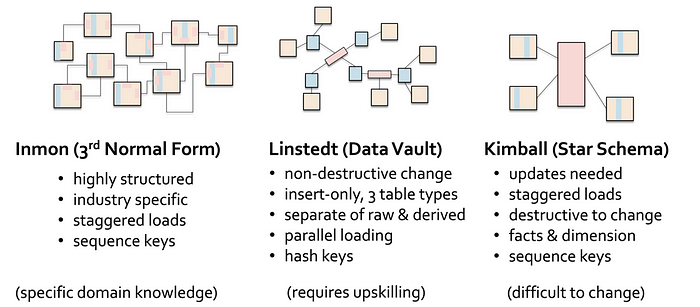
The challenge for temporal surrogate integer keys (as you may have already realised) in data modelling is that there is a required sequence to the load order of these related tables you will need to join on. You must load a fact table after all the related dimensional tables have been loaded (also known as “a staggered load”) or risk using default surrogate key values to denote late-arriving records. The same is true if a data vault is durable surrogate integer key based, load the hub table first, then the related link and hub-satellite tables and then finally the link-satellite tables. Durable surrogate hash keys on the other hand means you can load related data vault tables in parallel, however the cost in doing so is in the generation of surrogate hash keys. For a data model, it is crucial that a generated surrogate hash key is unique and therefore you must choose a cryptographic hash function with the minimum algorithm strength to guarantee uniqueness per input value into the hash function. The most common hash functions used in a data vault are the following (ordered by strength):
- MD5 (message digest 5) — output size: 128 bits (16 bytes), commonly supported by most database systems, however vulnerable to hash collisions, see: bit.ly/3enR6HG
- SHA-1 (secure hash algorithm) — output size: 160 bits (20 bytes) with one collision reported (ever), see: bit.ly/2V7GzbV and shattered.io
- SHA-2 — output size: 256 bits (32 bytes), no collisions reported yet.
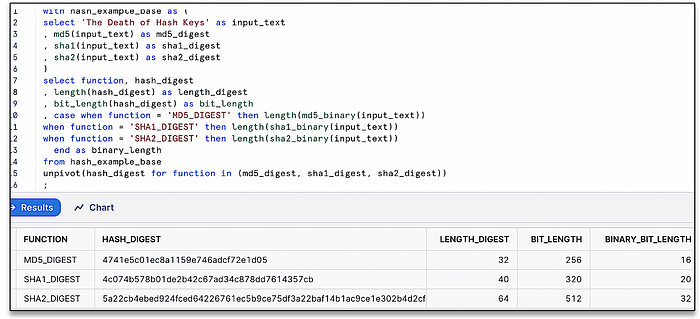
For more on hash collision probabilities see bit.ly/37O3rT3
Does a surrogate key mean anything beyond the act of joining related tables efficiently?
The answer is “no”, joining of data to retrieve the outcomes you need must happen in-database using the technology that supports it. Surrogate keys should never propagate into business intelligence tools or in the outcome of reports and dashboards, they have no meaning beyond the applicability for joining that data in the first place and your business users have no need (or interest) to see them either.
Is there any value in bringing in source-system/application surrogate keys into an analytics platform or data warehouse?
Yes, but recognise that these are not your keys and are susceptible to change if the source application is reloaded. They may serve the purpose of proving where the record came from and perhaps help in retrieving what the business key is for a record in pre-staging but nothing else. They have no business context.
We have discussed these topics extensively and here are more articles on the subject as it relates to data vault you can explore:
- A Rose by any other name… wait.. is it still the same Rose?- bit.ly/3xlFK0s
- Business key treatments — bit.ly/2YnlSh0
- Data Vault on Snowflake: Performance Tuning with Keys — bit.ly/3pVH5wl
What a data platform does with hashing
Implicitly, hash functions are utilised in database technology to achieve efficiencies that are hidden to the database user. Depending on the database techniques you’re using, different hash functions are used to efficiently accomplish uniqueness, distribution and performance.
For example (this is not an exhaustive list),
- Query optimisation: hash-joins (also-dubbed “build and probe”), a SQL engine will decide the type of join algorithm it will use underneath your SQL query based on the statistics it knows about the tables you’re joining. Smaller tables are hashed into memory in the build-phase, and each record in the join is used to probe the larger middle table in parallel. See: bit.ly/3PNZJgr
- Query optimisation: hash-based aggregation, this is for aggregating over large datasets and/or high-cardinality group-by columns from potentially an unordered input. Hashing helps distribute the input data between computing nodes to solve an aggregation in parallel.
- Data sketches: bloom filters are used in distributed computing to dynamically assist in record retrieval. A simple way to think of a bloom filter is that the algorithm can be used to determine in what location a value will not be found and in the remaining locations where it could be found. The larger the memory allocated to a bloom filter is, the higher the accuracy of the algorithm. Bloom filters are used in Cassandra to assist in determining in which node a record you’re trying to retrieve exists and therefore the query engine does not need to interrogate every node to find the consistent state of that record. in Snowflake they appear in your query plan as “JoinFilters” and are used to help determine which micro-partitions will not contain the records needed for your query and the remaining micro-partitions that could contain those records (also known as dynamic pruning). Other data sketches include hyperloglog that estimates the number of distinct values with an error of a few percent, count-min sketch, approximate top-k, Jaccard similarity and minhash to name a few. See: bit.ly/3eWpEpv
Other implementations using hash functions implicitly include, SAS hash tables, Python dictionaries, Spark map data structures, Redis hashes and Postgres hash indexes. We could go on…
Hash functions are a mechanism used to optimise database platforms; when hashing columns into surrogate keys are we hashing what was already previously hashed?
The problems with Hash Keys
Let’s begin with the obvious,
Storage
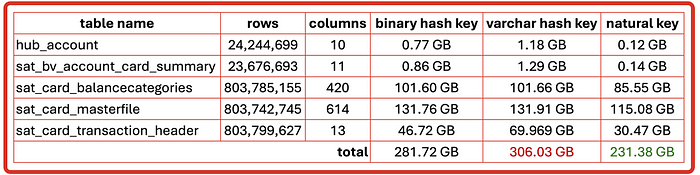
Although utilising surrogate hash keys as raw or binary is recommended to halve the storage needed to host a hash key column, the reality is that you’re consuming additional storage anyway without hashing at all. The other factor to consider is that hash digests are least efficient for compression, compression algorithms save primarily by encoding counts to repeated values in a string. There are virtually no repeated values in a hash digest thus compression has next to no effect on making this column smaller.
If you were to map to multiple hub and link tables you will therefore have as many hub-hash key columns and link-hash key columns.
This is taken from my other article comparing the storage in Snowflake with hash keys and without.
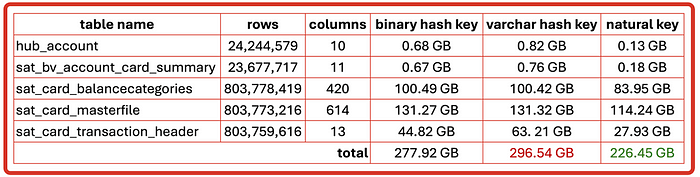
When optimising for partition pruning, surrogate hash keys should never be used as a cluster key. Satellite tables track true changes to the parent entity and therefore every table load could potentially force Snowflake to repartition the entire table if the table was clustered by the surrogate hash key. Table loads naturally cluster by the load date and therefore (as you have seen in the evidence above) explicit clustering on a load date is not necessary.
Computation
Computation of hash key values are not free, the more cryptographically unique an algorithm is the more CPU cycles required to generate the hash digest. You must use a surrogate hash key algorithm that guarantees no collisions could occur or risk joining unrelated data in your data vault. You need to ensure the data platform you choose to implement your data vault on supports the hash functions you need.
This is taken from my other article comparing the cost to load 100 million records in Snowflake with hash keys and without.
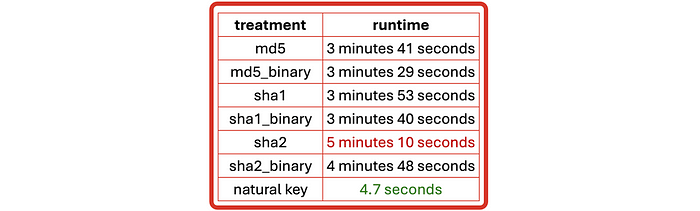
Generating hash digests are executed in the compute engine (virtual machine) and then persisted into the table where they are needed. To use those surrogate hash keys to perform SQL joins the hash keys must be loaded into the compute engine often with the natural key that will make sense to the business user, this implies waste (hash keys do not make sense to the end user — they will never query data based on a static surrogate hash key value).
Querying
Joining multiple satellite tables in data vault unavoidable, watch when happens when we do join data vault satellite tables without query assistance tables.

Now it may be that the natural keys used in this join were ‘generous’ because they compressed better than surrogate hash keys (and likely), however a major factor in a cloud architecture is where the computation takes place.
What should be done instead?
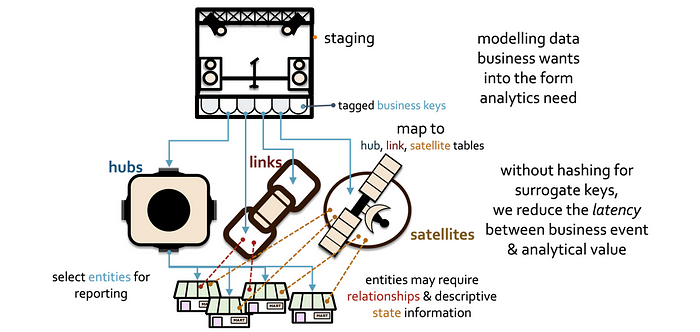
Metadata driven automation
An innovation introduced by Snowflake is the theme of mapping metadata pointers to the micro-partitions that represents data records in a collection of files as a table. This profound innovation has led to industry leading capabilities like zero-copy cloning and time-travel being possible in a single operation and without moving data at all. Apache iceberg takes that philosophy even further with the support of table snapshots and branching.
Graphical data modelling tools have always separated itself from the actual data too. Either you forward engineer a model to the physical implementation on disk or you reverse engineer the model to the visual tool from a physical implementation; in both scenarios a synchronisation step between data and metadata is necessary.
Surrogate hash keys themselves are nothing more than tools to enable some form of optimisation when joining tables together, and by the evidence we have shown in the previous section above, at least in Snowflake they do not seem to offer any benefit at all.
The relationship between a business object and its business key is always one-to-one because a business key has the following properties crucial to data modelling in general:
- Unique within its business domain.
- Stable, business keys should rarely (if ever) change. For what reasons could a business key value change, what would that do to the downstream data model? Could a change collide with an existing key?
- Simple, as a single column (preferably).
- Readable, for humans if they are business keys humans depend on to interact with the business.
- Consistent across systems
- Non-reusable to represent another business object
- Aligned to business processes
A business key is defined and designed by the business, it is a ‘forever’ binding to the business object it is created for, and that relationship is embedded in the metadata of the organization. Without a business key, you cannot reliably and uniquely identify a business object in an organization’s information systems landscape.
Surrogate hash keys are created in the data vault table load and then discarded after performing the SQL joins between related data vault tables. They are a tariff on the management of a data vault model. If you do not need to create them, then don’t.
Instead, when loading (these operations are done once in defining the data pipelines),
- Tag what are business keys in the incoming data
- Map to where those keys will load (one or more hub tables, zero or more link tables, one or more satellite tables that hang off a hub or link table).
- Use business key collision codes if necessary
Use that same metadata to:
- Join related tables exclusively using metadata to ensure joins are performed using the natural keys with the business key collision code columns. SQL savvy modeller and analysts will remember to include all the correct columns to perform join conditions on, however metadata driven join operations (no-code) will guarantee it.
- Selectively deploy query assistance tables like PITs and Bridges for your information mart layer and information marts in general.
- Manage true changes based on the cadence and set of changes required.
- Support a semantic layer and ultimately a knowledge graph.
The views expressed in this article are that of my own, you should test implementation performance before committing to this implementation. The author provides no guarantees in this regard.
