Data Vault is Information Mapping

At the heart of a data-driven organization is the automation of business processes and information state. Core business capabilities and that information state based around business objects and the interactions between business objects grows horizontally as the business evolves and vertically as we store previous information states. Vertical growth is the basis of enterprise analytics, horizontal growth is a symptom of business process evolution.
Software architecture (business process automation) is complex as it hosts a combination of software architecture frameworks, preferred software languages and the optimal storage medium or data model type to support that software application. In order to support vertical growth, software application state information (captured as data) must be ingested into a uniform canonical data model we call the enterprise data vault model and ingest that data into a data platform optimised for columnar analysis.
Pushed or pulled, structured, semi-structured or even unstructured data must be mapped into those three things every business in whatever industry tracks:
- What are my business entities and how do I uniquely identify them, describe them
- What other business entities do these entities relate to, interact or transact with
- What is the information state of those entities we historize as true changes
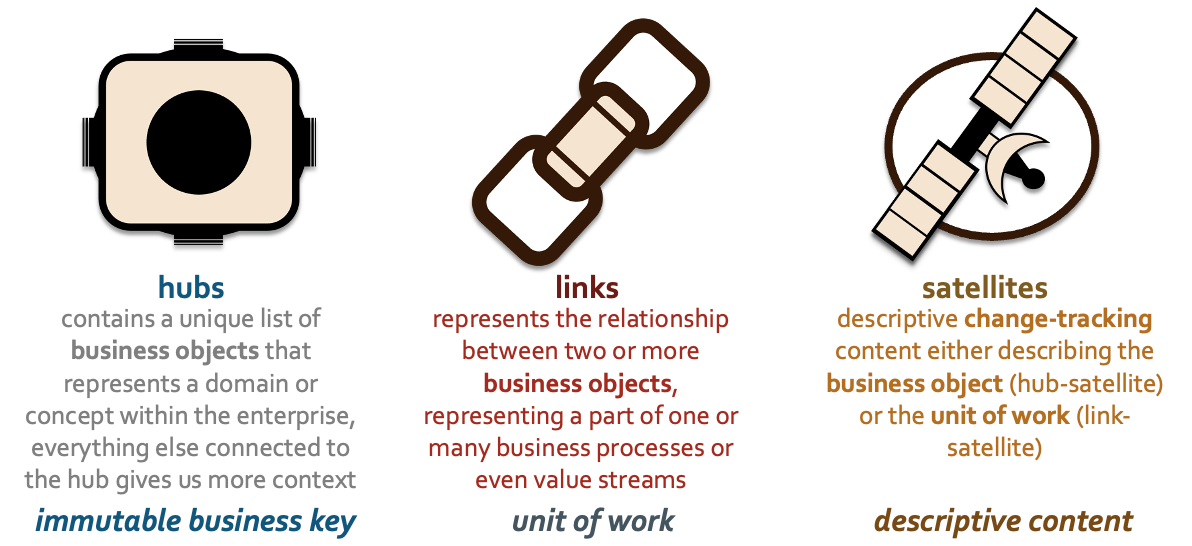
A data vault is made up of only three table types and the three table types merge and consolidate your business process data to form the basis of a business ontology; a data representation of the information landscape automated by business software. With these three structures I can replay or revisit the enterprise’ corporate memory as far back as required.
Let’s map your software application landscape to a data vault.
Hub Tables = Business Objects
A hub table should be a one-to-one representation of what your business considers to be a business object. The nuance in this table type is how it represents a business object uniquely within your enterprise. Let’s explore the basics to get started,
- A business object is uniquely identified by a business key. It is this business key that the business itself interacts with and is used to trace everything they want to know about a customer, account, contract or even a product. These are uniquely identified as customer id, account id, contract id and product id respectively.
- The unique id should be used universally across the application software landscape however the operational reality is that they are often not. How we deal with these scenarios is what we in the data vault community term as passive integration.
- Each business object as a classification must carry a description or definition universally recognised by the business. This is always an activity that must have business involvement to ensure the correct nomenclature is used when business initiatives lead to IT automation.
- In recognition that there is some complexity in business keys across the software landscape means that a data governance function must exist to take ownership and accountability for solving these complexities.
- The business key is stable and doesn’t evolve into another key. Surrogate keys are potentially not stable and could change should an application be reloaded. This is the top reason why we do not load surrogate keys into a hub table. The other unique identifier we do not load into hub tables are government issued identifiers.

- Data vault training calls it a ‘collision code’ however we do find that data engineers default the value of this code as the equivalent to a source-system id. This is an incorrect interpretation of this column and why a better name for this column might be a ‘namespace id’. By defaulting the value of this column to a source-id we end up with far more entries in the hub table then is necessary and more table joins and technical debt to resolve these complexities you introduced yourself. The word ‘collision’ is too closely related to hashing, i.e. to create a surrogate hash key. The collision’s outcome is indeed in the surrogate key value, but the collision happens in the business key itself.
Now that we know that hub table definitions should be a near one-to-one representation of business objects within an enterprise, how many hub tables do you think you should have? Hub tables integrate software application data at the universally agreed point of integration of a business object, the business key. What this implies is that the business key itself integrates horizontally for software applications and vertically between data, application business architectural views. Like sticking a rod through each layer holding all related data together for a business concept.
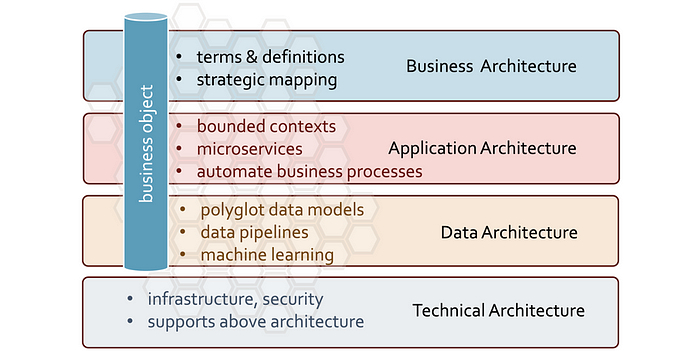
What does this revelation mean to you? Well, this is where you earn your wages (so to speak). If you do not build hub tables that represent your business objects you are simply,
- Not profiling what in fact is really a business object.
- Not considering business architecture, business ontologies or not future proofing your enterprise data model for inevitable change.
- Looking for something your data vault model needs to join on. An anti-pattern we see those building data vault models, the so-called weak hub tables
- Defining reference codes as business keys and which should instead be considered as dependent child keys. Reference data should not be modelled into a data vault model as hub, link and satellite tables but instead used as a reference to enrich your data for downstream data analytics.
- Creating hub constructs doomed to fail such as including date fields and other non-identifier data elements into a hub key perverses the original intent of an information map. (aka keyed-instance-hubs — a unique method of introducing technical debt into a data vault model).
Can a business object have multiple business keys? Yes, one of your data sources must supply a mapping between those keys but you must agree on which business key the business will interact with downstream and consistently pick that key.
Can multiple business objects share the same key? No, to your business a business key value is one to one with the business object. The same mapping applies, and you need to confirm which key is universally used for a business object (forever, and no exceptions). All analytics a business refers to will be based on that key.
Where defining an ontology earns your wages…. how we ensure we automate business objects through to the software information landscape is the same business object and carries the same business object definitions and descriptions.
To conclude:
- the business key is the universally agreed upon integration point for all software applications (data sources) — horizontal integration
- the business key is the universally agreed upon integration point between the software landscape and business architecture domain — vertical integration.
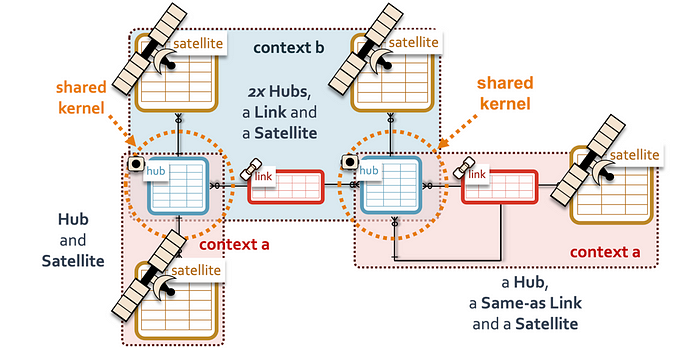
- business keys are universally applied and are immutable across bounded contexts (an enterprise may have many bounded contexts). Each context enriches a business object through their life cycle in an enterprise.
- Lastly, business keys are always, always, always of a string data type. Defining a numeric business key as a numeric data type is stupid.
Immutable business keys remain the same and so should your hub tables, although your software landscape evolves and new business processes are loaded and captured into the data vault, rarely should you see new hub tables in an established enterprise data vault model.
The Value of “Connected Data”?
While data is everywhere; enabling and supporting business processes through automation; alone that bounded context does not have the enterprise view of that data in context to all other data within an enterprise’ portfolio — the organization’s corporate memory. The value of data in that bounded context has bounded value, connected to other data it has the potential for boundless value. Like purchasing a physical asset, data must be accompanied with the rigour of curation to ensure trust in the value of that data.
In this article we labelled the zone responsible for data integration as the coherent zone, a definition of coherent data is “data that lives a connected life”. Given that we intend to build analytical platforms focussed on those three main things every organization manages (business objects, relationships and information state), the reliable method to connect that data is through the business object’s business key. All other data about that business object adds to the interactions, transactions, relationships and information state of those business objects; it adds context. Modelled into a reliable, repeatable and resilient form, the data model designed as the confluence of an enterprise’s data landscape will also ingest that data as an organisation’s corporate memory. The data model must be auditable.
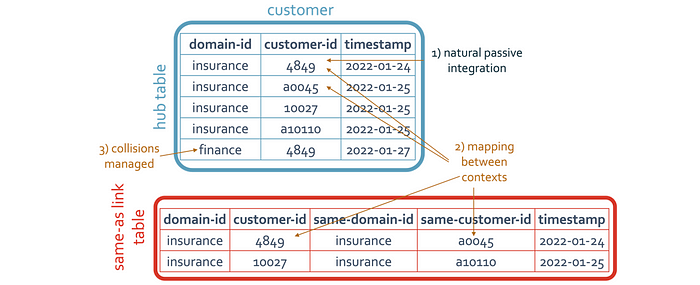
Managing business keys across your software landscape includes the efforts to extract those unique business object identifiers from structured, semi-structured (JSON, XML) and unstructured payloads (documents, audio, video). For any of this data to have value to the organization, business keys must exist to understand what the context of that data. Regardless of the source structure type, the same management of business keys and content curation is expected.
Data vault’s hub table construct is the central store of those business keys; all other contexts are mapped to link and satellite tables respectively.
Next, let’s discuss the justification for link tables…
Link Tables = Business Processes
A common objection to link tables I encounter is that it does not historize anything. It is the most contentious table type in a data vault. Link tables capture the truth about the interactions between business objects. This is a fact that happened, an event, relation, transaction happened between these business objects, and we capture that interaction in a link table. There are a few nuances to this historical recording of interactions, namely:
- It is at least a binary relationship; the rule should be written as the following: “a link table records the relationship between at least two business objects represented by at least one hub table”. The recording of relationships is between the immutable key and sometimes that is represented by multiple business keys within the same hub table.
- A binary relationship is not a default recording of a relationship, consider the cardinality between relationships and whether breaking up a unit of work conflicts with your ability to recreate a source record at any point in time. We don’t ban breaking up the unit of work, the cardinality between those business objects is such that it could be possible to break it up and you are still able to recreate the business process from where that data came from.
- A relationship can end and how we define the end of a relationship is the absence of a business key in that relationship. In a data vault we coalesce the null value in a business key column as the zero-key (some call it the null key). This concept ensures that a many-to-many link table structure can always serve other cardinalities like one-many, zero-to-many. Zero key in the data vault makes the link table flexible to any cardinality. Zero keys naturally occur in hub tables and do not need pre-loading into the hub table to ensure the link table has something to join to. Zero-keys in a link table ensures that inner join will always work even if some of the relationships change between some of the business objects.
- What the source system defines as a relationship is not necessarily the same as how the business sees a business process. If you need to define the relationship as the business sees it, consider building a business vault link table which will be based on the raw vault link table and the idempotent business rule to construct that business vault artefact.
- The relationship can include a relationship between the same business object type. What does this mean? Data vault discusses three types of link tables,
o Link table — unit of work, relationship, interaction or event between business objects.
o Same-as link table — as above, but the link table references the same hub table. We see this occur when mapping keys between source systems or even when master data management match-merge keys are used as a data source.
o Hierarchical link table — as above but implies a parent child relationship between entities within the same hub table.
Well, what if the unit of work includes a combination of the relationships we just mentioned? Use a single raw vault link table, there is almost no need to separate these into individual link tables. A Link is a link is a link, in fact the way one would query a link table does not change.
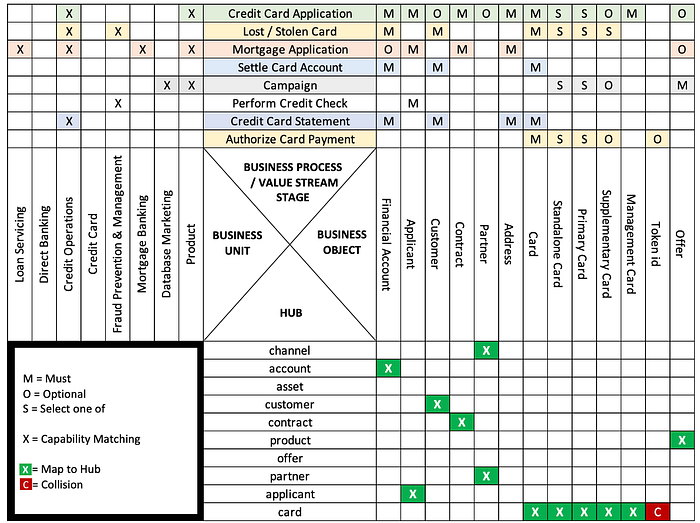
Can a link table be sourced from multiple source-applications? Yes and no, conceptually think about what you are creating and if it is something that is explicitly defining a relationship like a same-as or hierarchical relationship then this could add value. The tricky portion of this consolidation is tracking where each record came from, consider a record tracking satellite table for this instance. The alternative thought pattern with regards to multi-sourced link tables is simply this, do we have repeated or redundant business processes achieving the same thing? Ideally for such a relationship you should have a single version of the truth which leads to an enterprise architecture question of whether the business is running overlapping business processes.
The nuance of Link Effectivity
A link table uniquely identifies some interaction between business objects, a tricky concept you would need to think about is, would an original relationship return to its previous state? If you know this could happen then you should consider the effectivity satellite table pattern. Attempting to add start and end dates to the link table itself is stupid, it breaks the link table pattern and every query needing to traverse the lineage between hub tables must now also by default resolve this introduced complexity into the link table.
The effectivity satellite and driver key model concept is important to understand because it makes the link table relationship it depicts flexible to multiple modelling concepts around a driver key, furthermore, the single link table can have multiple driver keys defined, and that definition does nothing to the integrity of that link table.
Satellites Tables = Finite and Free-Form State
This is as close to a dimensional model as data vault gets, a satellite table tracks the true changes to the state of a business object or relationship. The only difference between the traditional Kimball Slowly Changing Dimension (SCD) Type 2 and a data vault 2.0 satellite table is that the satellite table does not have a physicalised end date column to each record, instead that column is virtualised through a view using the window lead function. What is the point of doing that? Ingestion is far quicker because SQL updates are expensive. The task of finding the appropriate record at a point in time is palmed off to the query techniques you use, and the data vault practice does indeed cater for that.
But before we delve into that let’s discuss satellite splitting. The concept is not about taking an existing satellite table and splitting that into multiple satellite tables but instead ensuring that the descriptive information we capture is allocated appropriately to represent the state change of either a business object or a relationship. This is extremely important, because an attribute may only be relevant because of the relationship between business objects, or an attribute may only be describing a business object within those transactions. An easy question you can ask yourself to decide is, does this attribute exist without the other business object in this interaction. The benefit to adopting this mindset in your data model is profound:
- You can easily identify changed state to a business object within a single hub-satellite table.
- You’re not replicating data in each transaction in your link-satellite table.
- You could potentially be isolating personally identifiable information (PII) and therefore making it easier to deal with GDPR article 17 requests.
- Batched transaction data can be supported by satellite tables with dependent-child keys hanging off your link table, easily. Your dependent-child key in this instance is the transaction id (aka an intra-day key).
This is what we talk about when we discuss shift-left modelling, solving the complexities of your polyglot data upfront so that the queries retrieving that data does not have to. Each raw vault satellite table is single sourced and independent from all other ingestion data pipelines. This ensures that there is no complexity on managing satellite table loads and it also ensures that no refactoring is required if the source data evolves. Yes, this also means that you should not change column names in the raw satellite table or risk having to deal with technical debt you introduced into the data model yourself.
What happens when the data supporting a raw vault does evolve? Well,
- Profile the new or deprecated column,
- Decide which satellite table the new attributes will map to
- Evolve the satellite table in place. Reloading a satellite table should not be required as doing so obscures the fact that you didn’t have that column in the first place.
This phenomenon is known as ‘3-valued logic’, much has been written about how SQL interprets a null, in the context of an evolving satellite table, the lack of the column in the first place is different from having the column and there is a null in it.
Mapping to satellite tables generally has three main cadences,
- Mapping to a regular satellite table with single record state changes
- Mapping to a satellite table with a dependent-child key and therefore tracking to the sub-state of a parent entity
- Mapping to a multi-active satellite table which tracks changes to a set of records per parent entity.
By parent entity we mean the parent could be either a raw vault hub table, raw or business vault link table.
Regarding mapping to business vault satellite tables, the source of these satellite tables is a transformation between what is captured in raw vault and perhaps other business vault artefacts. What is important to consider here is the following:
- Consider physicalising business vault satellite tables, the business rule implementation is separated from the business vault structure and therefore ensuring the highly flexible nature in terms of business rule code evolution to the business vault. An evolved business rule may be applicable only from a point in time and this segregation ensures that the application code can evolve freely without hardcoded dates in them.
- Business vault satellite tables may be multi-sourced, consolidating, combining, rationalising data or even be a true-change structure used for a feature store. Business vault satellites are never copies of raw vault satellite tables even for just renaming column names (if this is required consider deploying a view over the satellite table for that purpose).
- Data vault must be bi-temporal to support this pattern — load and applied dates.
Do we take some descriptive attributes from a source or all of it? Ultimately you would have to decide because there are dividing opinions on it and all of them realistically have merit. The broader view on this topic is how you have defined your overall data architecture zones and layers. Raw vault satellite tables take polyglot data the business wants and conforms that data into the form they need. As we stated, raw vault does not change any of the content (bar the application of hard rules), what we have done is provide the auditable data source for business objects and relationships. Except for source system application metadata that may be included in those data sources, everything else is business data about business objects and business processes. We should take all that business data, even if the source has 600+ columns, and load that into the raw vault. Satellite splitting also ensures that we can enact GDPR article 17, and the rest of the data can remain unimpacted. Cloud-based object storage (files) means keeping this data as true changes is cheap, not keeping this and failing regulatory compliance may not be.
Finally, dimensional data modellers usually compare data vault modelling to dimensional modelling, therefore we will map that here.
() — optional
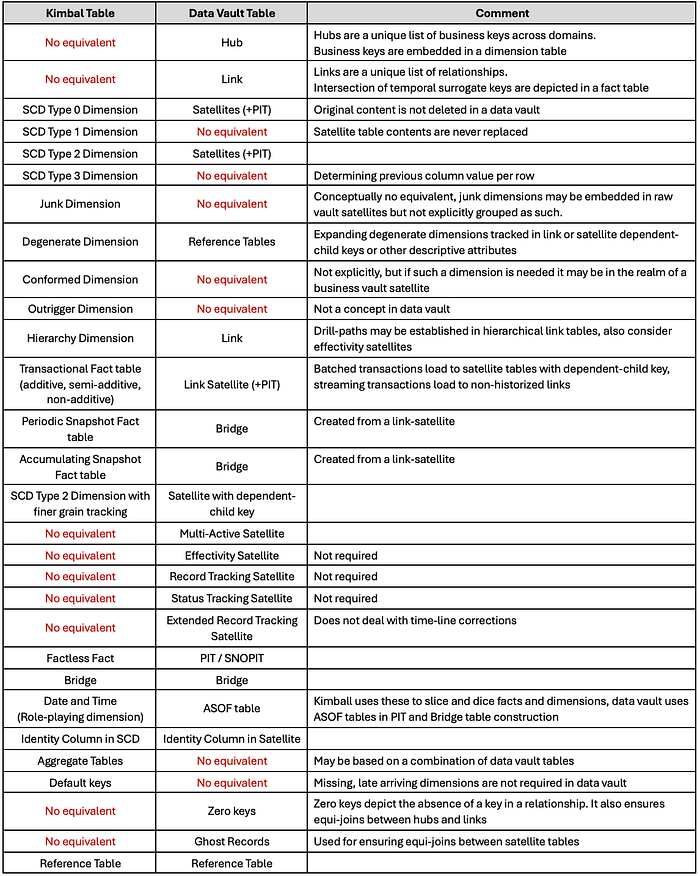
Dimensions created from satellite tables may include the use of PIT tables to bring related data together. Because PITs and Bridges are ephemeral and do not possess the same auditability requirements as business vault satellite tables they should not be considered business vault artefacts. These are a part of information delivery, PITs and Bridges may include raw and business vault artefacts in its construction.
Data vault does not replace dimensional modelling, but it does serve as its base. Therefore, the value of this exercise is mapping what data vault artefacts are likely to support a dimensional model.
References
- Learning Data Vault is Like Learning How to Make Beer! bit.ly/2ZYGpJP
- Data Vault Recipes bit.ly/2WEWCSw
- Say NO to Refactoring Data Models! bit.ly/3iEiHZB
- Rules for an almost unbreakable Data Vault bit.ly/4djNchE
- More Rules for an (almost) unbreakable Data Vault bit.ly/3y4jeyD
The views expressed in this article are that of my own, you should test implementation performance before committing to this implementation. The author provides no guarantees in this regard.
